What is Apache Spark and why is it important
Apache Spark is an open-source, distributed computing framework designed to process and analyze large volumes of data with exceptional speed and efficiency. Built to address the limitations of traditional data processing frameworks, Spark offers a unified platform for various data-related tasks, including batch processing, real-time streaming, machine learning, and graph processing.
Spark offers a variety of APIs for different programming languages, including Scala, Java, Python, and R. These APIs provide higher-level abstractions like DataFrames and Datasets, which simplify data manipulation and analysis by offering structured and SQL-like interfaces.
Apache Spark: Unveiling Its Features and Advantages
In the ever-evolving landscape of data processing, Apache Spark has risen to prominence as a powerhouse framework that revolutionizes the way organizations handle and glean insights from vast datasets. As we embark on this exploration of Apache Spark’s features and advantages, we uncover its underlying capabilities that make it an indispensable tool for modern data processing.
Features of Apache Spark
1. In-Memory Computation
One of the standout features of Apache Spark is its capability for in-memory computation. By storing intermediate data in memory, Spark dramatically reduces data access times, leading to significantly faster processing speeds. This feature is especially valuable for iterative algorithms and tasks that require quick access to data.
2. Distributed Computing
Spark’s distributed computing model harnesses the power of clusters. It distributes data and computation across multiple machines, enabling parallel processing. This not only enhances processing speed but also allows Spark to scale seamlessly as data volumes grow.
3. Resilient Distributed Datasets (RDDs)
RDDs lie at the core of Spark’s architecture. These fault-tolerant, immutable data structures form the foundation of data manipulation. RDDs are not only the data containers but also the entities that enable Spark’s parallel processing and recovery mechanisms in case of failures.
4. Versatile Libraries
Spark comes bundled with a variety of libraries that cater to diverse data processing needs. MLlib provides tools for machine learning, enabling the development and deployment of predictive models. Spark SQL offers SQL-like querying capabilities for structured data, while GraphX empowers graph processing and analysis.
5. Directed Acyclic Graph (DAG)
Spark’s computation model relies on a Directed Acyclic Graph (DAG). This graph represents the sequence of transformations applied to data, optimizing the execution plan. The DAG approach minimizes data movement and enhances processing efficiency.
Advantages of Apache Spark
1. Speed and Efficiency
The in-memory processing capability coupled with parallelization results in blazing-fast data processing. This speed is pivotal for real-time analytics, iterative algorithms, and other scenarios demanding rapid insights.
2. Unified Processing Platform
Spark’s versatility eliminates the need for using different frameworks for distinct tasks. Whether it’s batch processing, stream processing, or machine learning, Spark offers a unified platform to streamline processes and reduce complexity.
3. Fault Tolerance
With RDDs and lineage information, Spark can recover lost data in case of node failures. This inherent fault tolerance ensures the reliability of data processing tasks, minimizing disruptions.
4. Scalability
Spark’s distributed nature allows seamless scalability. As data volumes increase, additional resources can be added to the cluster to maintain performance levels.
5. Rich Ecosystem
The ecosystem of libraries surrounding Spark enriches its capabilities. These libraries address a wide spectrum of data processing needs, augmenting Spark’s utility across various domains.
Overview of Apache Spark Architecture
At its core, Apache Spark embraces a flexible and modular architecture designed to optimize data processing across various workloads. The architecture’s modularity allows Spark to accommodate diverse requirements, from batch processing to real-time stream processing and machine learning.
Key Components of Spark Architecture
1. Driver Program
The Driver Program serves as the entry point for Spark applications. It consists of the user’s application code and defines the transformations and actions to be executed on the data. The Driver Program interacts with the Spark Master to coordinate the execution of tasks across the cluster.
2. Cluster Manager
The Cluster Manager is responsible for allocating resources and managing the cluster’s nodes. Apache Spark supports various cluster managers, including Standalone, Apache Hadoop YARN, Apache Mesos, and Kubernetes. The Cluster Manager ensures efficient resource allocation and scaling based on the application’s requirements.
- Standalone Mode is an out-of-the-box cluster manager that comes bundled with Apache Spark. Unlike other cluster managers that are part of larger ecosystems, Standalone Mode requires no external dependencies, making it a convenient choice for setting up Spark clusters quickly.
- Apache Hadoop YARN (Yet Another Resource Negotiator) is a widely used cluster manager within the Hadoop ecosystem. It serves as a resource manager and job scheduler, ensuring efficient utilization of cluster resources. YARN’s resource allocation and management capabilities make it a compatible choice for running Apache Spark applications.
- Apache Mesos is a cluster manager known for its ability to efficiently share resources across different applications. It abstracts the cluster into a single pool of resources, allowing multiple frameworks, like Spark, to operate concurrently. Mesos focuses on maximizing resource utilization while maintaining isolation between tasks. (Deprecated now)
- Kubernetes is a popular open-source container orchestration platform that manages the deployment, scaling, and operation of application containers. While not a traditional cluster manager, Kubernetes can be used to deploy Spark clusters using its features for resource management, scaling, and fault tolerance.
3. Spark Master
The Spark Master is a pivotal component that oversees the allocation of resources and scheduling of tasks. It communicates with the Cluster Manager to acquire resources and then coordinates the assignment of tasks to Worker Nodes.
4. Worker Nodes
Worker Nodes, also known as Executors, are the worker units in the Spark architecture. They execute tasks assigned by the Spark Master and manage data storage in memory and on disk. Each Worker Node manages its resources and carries out computations on the data partitions stored locally.
5. In-Memory Computing
At the heart of Apache Spark’s architecture lies its ability to perform in-memory computing. This capability allows data to be stored in memory, drastically reducing data access times compared to traditional disk-based processing. This approach accelerates data processing, making Spark exceptionally fast for iterative algorithms and repeated computations.
6. Resilient Distributed Datasets (RDDs)
The concept of Resilient Distributed Datasets (RDDs) is fundamental to Spark’s architecture. RDDs are immutable, fault-tolerant collections of data partitions that can be processed in parallel. They facilitate data sharing across tasks and nodes, enabling the recovery of lost data in case of node failures.
Execution Flow in Spark Architecture
- The Driver Program defines the transformations and actions to be performed on the data.
- The Driver Program interacts with the Spark Master to request resources for executing tasks.
- The Spark Master communicates with the Cluster Manager to allocate resources in the cluster.
- Worker Nodes receive tasks and data partitions from the Spark Master and execute computations.
- Data is processed in-memory whenever possible, enhancing processing speed.
- The results of transformations and actions are sent back to the Driver Program for final processing or output.
Apache Spark Installation Guide
Installing Apache Spark marks the first exciting step towards harnessing the power of big data processing. In this comprehensive installation guide, we will take you through the process of setting up Apache Spark on your machine, whether for local development, experimentation, or learning purposes. Follow the steps below to embark on your Apache Spark journey.
Prerequisites
Before we dive into the installation process, make sure you have the following prerequisites in place:
- Java Development Kit (JDK): Apache Spark is built on Java, so ensure you have the JDK installed. You can download the JDK from the official Oracle website or opt for open-source alternatives like OpenJDK.
Installation Steps
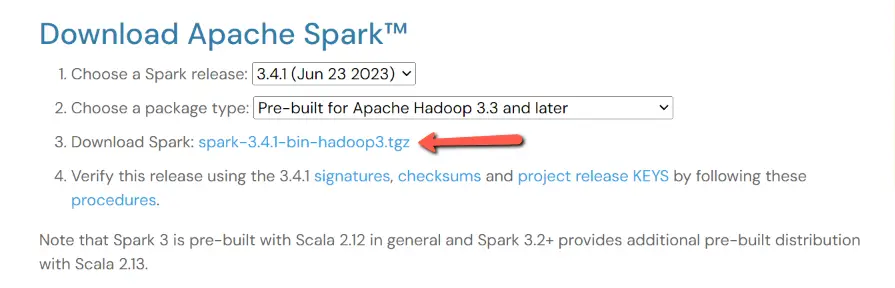
Step 1: Download Apache Spark
- Visit the Apache Spark official download page.
- Choose the Spark version that suits your requirements. We recommend selecting the “Pre-built for Apache Hadoop” package unless you have a specific Hadoop distribution you want to use.
- Click the download link corresponding to your chosen version. In our case we are downloading spark-3.4.1-bin-hadoop3.tgz
Step 2: Extract Spark Archive
- Once the download is complete, navigate to the directory where the Spark archive is saved.
- Extract the archive using the following command
tar -xf .\spark-3.4.1-bin-hadoop3.tgz -C C:\sparkStep 3: Add winutils.exe
Apache Spark, despite being a separate project, shares some components and concepts with Apache Hadoop, an ecosystem for distributed storage and processing of large datasets. Spark’s original design involved working with Hadoop Distributed File System (HDFS) and other Hadoop components.
In Hadoop, file and directory permissions are managed differently than on Windows. Hadoop uses Unix-style permissions, whereas Windows uses its own security model. When Spark interacts with HDFS-like file systems, it expects certain Unix-like permissions, and this is where <strong>winutils.exe</strong> comes into play.
Download <strong><a rel="noreferrer noopener" href="https://github.com/cdarlint/winutils/" target="_blank">winutils.exe</a></strong> and hadoop.dll then put both into C:\spark\spark-3.4.1-bin-hadoop3\bin folder. Check different versions of winutils.exe and use accordingly for your requirements. In our case we are using hadoop-3.3.5 .
Step 4: Configure Environment Variables
- Set the SPARK_HOME environment variable to the directory where Spark is extracted: For Windows (using PowerShell run as administrator):
[System.Environment]::SetEnvironmentVariable('SPARK_HOME','C:\spark\spark-3.4.1-bin-hadoop3',[System.EnvironmentVariableTarget]::User) - Set the HADOOP_HOME
[System.Environment]::SetEnvironmentVariable('HADOOP_HOME','C:\spark\spark-3.4.1-bin-hadoop3',[System.EnvironmentVariableTarget]::User) - Add the Spark binaries to your system’s
PATHenvironment variable: For Windows (using PowerShell):$p = [Environment]::GetEnvironmentVariable("PATH", [EnvironmentVariableTarget]::User); [System.Environment]::SetEnvironmentVariable('PATH',$p + ";%SPARK_HOME%\bin",[System.EnvironmentVariableTarget]::User)
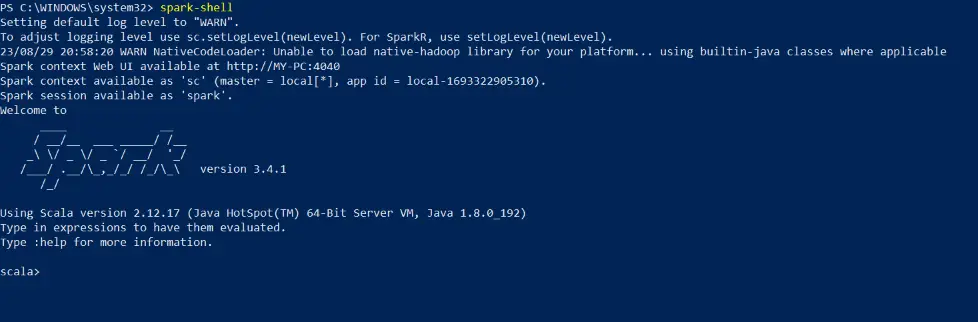
Step 5: Test the Installation
Now close the power shell and open again (run as administrator) then run the following command to launch the Spark shell:
spark-shellIf the Spark shell opens without errors and you see the Spark logo, congratulations! Apache Spark is successfully installed on your machine.
SparkSession & SparkContext
SparkSession and SparkContext are both fundamental components in the Apache Spark ecosystem, serving as entry points to interact with Spark’s functionality. While they serve similar purposes, SparkSession is a higher-level concept introduced in Spark 2.0 that encompasses the functionalities of both SparkContext and other contexts, simplifying the interaction with Spark.
Creating SparkSession and SparkContext
Creating a SparkSession is the recommended approach, as it automatically creates a SparkContext under the hood while providing additional benefits. Here’s how to create them:
Creating a SparkSession:
from pyspark.sql import SparkSession
# Create a SparkSession
spark = SparkSession.builder
.appName("sparktpoint")
.config("spark.some.config.option", "config-value")
.getOrCreate()
spark.stop()Creating a SparkContext (Legacy):
from pyspark import SparkContext
# Create a SparkContext
sc = SparkContext(appName="sparktpoint")
sc.stop()
Spark Components
Apache Spark is a powerful and versatile open-source big data processing framework that consists of several core components. Each of these components plays a crucial role in enabling distributed data processing, analytics, and machine learning. Here are the key components of Apache Spark:
Spark Core
The foundation of the Spark framework, Spark Core provides the fundamental functionalities for distributed data processing. It includes task scheduling, memory management, fault recovery, and the Resilient Distributed Dataset (RDD) data structure, which is a fundamental building block for distributed data processing
Resilient Distributed Datasets (RDDs)
RDDs are the fundamental data structure in Spark. They are immutable, distributed collections of data. RDDs are the basis for all of Spark’s other data structures.
RDDs are created by either loading data from a distributed file system or by transforming existing RDDs. Once an RDD is created, it cannot be modified. However, it can be transformed into new RDDs.
Here is an example of creating an RDD from a file:
Transformations
Transformations are operations that are performed on RDDs. They are lazy, meaning that they are not executed until they are needed. Transformations are what make Spark so efficient.
Here are some examples of transformations:
map(): Applies a function to each element of an RDD.filter(): Filters an RDD by elements that match a predicate.reduce(): Reduces an RDD to a single value by applying a function to pairs of elements.
Here is an example of using the map() transformation:
val words = data.map(_.split(" "))This code creates a new RDD of words by splitting each line in the original RDD by spaces.
Actions
Actions are operations that produce a result from an RDD. They are executed immediately. Actions are what Spark uses to read and write data, and to perform computations on data.
Here are some examples of actions:
collect(): Collects all elements of an RDD to the driver program.saveAsTextFile(): Writes an RDD to a file.count(): Counts the number of elements in an RDD.
Here is an example of using the count() action:
val numWords = words.count()This code counts the number of words in the RDD.
Spark SQL
Spark SQL is Spark’s interface for structured data processing. It allows you to run SQL queries alongside Spark programs.
from pyspark.sql import SparkSession
#Creating a SparkSession
spark = SparkSession.builder.appName("sparktpoint.com").getOrCreate()
#Loading from a CSV file
df = spark.read.csv("people.csv", header=True, inferSchema=True, sep="|")
#Running SQL Queries
df.createOrReplaceTempView("people")
result = spark.sql("SELECT * FROM people WHERE age >= 25")
result.show()
#Closing the SparkSession
spark.stop()- Spark SQL seamlessly integrates with DataFrames and Datasets.
- It supports various data sources like Parquet, JSON, and JDBC.
DataFrames
DataFrames are a powerful data structure in Spark that provide a rich set of features for working with structured data. DataFrames are similar to RDDs, but they provide a more concise and expressive way to represent data. DataFrames are also more efficient than RDDs for many operations, such as filtering, sorting, and aggregation.
Creating DataFrames
DataFrames can be created from a variety of sources, including:
- CSV files
- JSON files
- Parquet files
- Hive tables
- Spark SQL tables
Here is an example of how to create a DataFrame
# Creating a DataFrame from a list of dictionaries
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("sparktpoint.com").getOrCreate()
data = [{"name": "Alice", "age": 28}, {"name": "Bob", "age": 22}]
df = spark.createDataFrame(data)
df.show()- DataFrames allow you to perform SQL-like queries on your data.
- They are designed for structured data with named columns.
Datasets
Datasets combine the best of both worlds, offering the strong typing of RDDs with the optimizations of DataFrames. Datasets are particularly useful when you need to work with semi-structured or strongly-typed data.
case class Person(name: String, age: Int)
val data = Seq(Person("Alice", 28), Person("Bob", 22), Person("Charlie", 35))
val dataset = data.toDS()
dataset.show()- Datasets can hold both custom objects and built-in types.
- They provide type safety and high-level operations.
Spark Streaming
In today’s data-driven world, the ability to harness real-time data is nothing short of a game-changer. Imagine making critical decisions, detecting anomalies, and responding to events as they unfold, all with the speed of thought. This is precisely where Spark Streaming steps onto the stage, offering a powerful solution for processing and analyzing data in real-time.
Spark Streaming, an integral component of the Apache Spark ecosystem, empowers organizations to tap into the wealth of information flowing in real-time from various sources such as sensors, social media, logs, and more. It takes the robustness and versatility of Spark’s batch processing capabilities and extends them seamlessly into the world of continuous data streams.
- Spark Streaming can handle data from various sources like Kafka, Flume, and more.
- It’s ideal for applications requiring low-latency data processing.
Spark MLlib
In today’s data-driven landscape, making sense of vast datasets and uncovering hidden patterns is the key to unlocking new opportunities and staying ahead in the game. This is where Spark MLlib emerges as your trusted ally, a powerful library within the Apache Spark ecosystem, designed to turn your data-driven dreams into reality.
Imagine having a tool at your disposal that not only simplifies but also accelerates the process of building, training, and deploying machine learning models. Spark MLlib does just that. It empowers both seasoned data scientists and curious beginners to harness the full potential of machine learning without the complexities often associated with it.
- MLlib supports classification, regression, clustering, and more.
- It integrates seamlessly with Spark’s ecosystem.
Spark GraphX
In the vast landscape of big data, some questions can’t be answered by simply sifting through rows and columns. They require a more intricate approach—one that understands relationships, dependencies, and connections. This is where Spark GraphX steps in, offering an exciting pathway into the world of graph analytics.
Imagine being able to decipher complex networks, social interactions, or dependencies within your data effortlessly. Spark GraphX, an integral component of the Apache Spark ecosystem, equips you with the tools to do just that. It’s like having a magnifying glass for your data, revealing hidden patterns and insights that might have remained elusive otherwise.
GraphX brings the power of graph processing and analytics to the world of big data. It’s not just about understanding individual data points; it’s about understanding how they relate to each other. Whether you’re in social media, healthcare, transportation, or any field where connections matter, GraphX is your ticket to uncovering valuable knowledge.
Apache spark monitoring
Monitoring Apache Spark is crucial to ensure the smooth and efficient operation of your Spark applications, identify performance bottlenecks, and troubleshoot issues. There are various tools and approaches for monitoring Apache Spark:
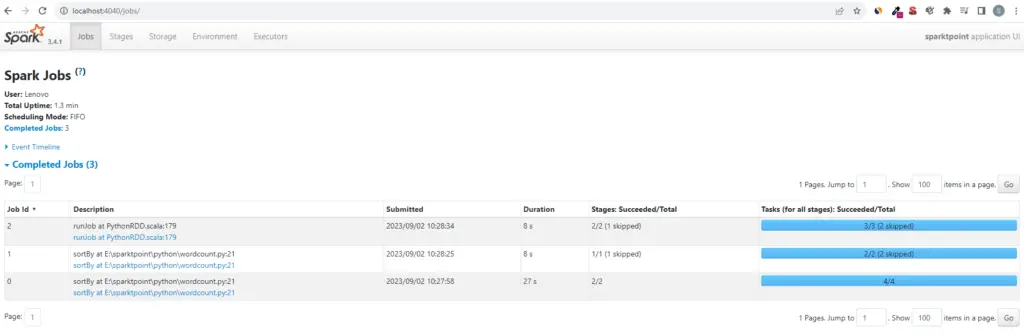
Spark Web UI
Spark provides a built-in web-based user interface that offers valuable insights into the status and performance of your Spark application. You can access it by default at http://localhost:4040 when a Spark application is running. It provides information about job progress, stages, tasks, and more.
Logging
Spark logs a wealth of information about its operation. You can configure logging to different levels (e.g., INFO, WARN, ERROR) and route logs to a central location for analysis. Tools like ELK Stack (Elasticsearch, Logstash, Kibana) can help manage and analyze logs effectively.
Ganglia and Graphite
You can integrate Spark with monitoring systems like Ganglia and Graphite for more extensive cluster-wide monitoring. These tools collect metrics from Spark and other cluster components, allowing you to visualize performance data over time.
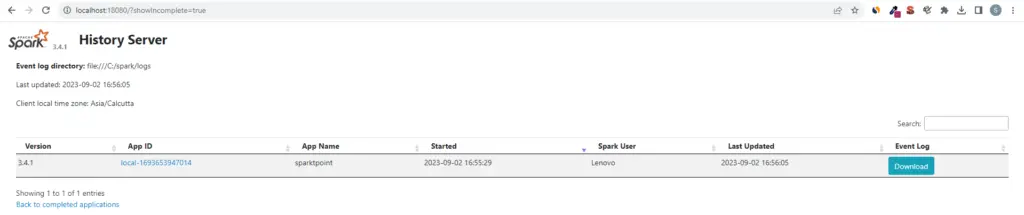
Spark History Server
Spark provides a history server that can be used to store and view historical data about completed Spark applications. This is particularly useful for retrospective analysis and debugging.
Configure Spark to Generate Event Logs
The Spark History Server is not enabled by default. To enable event logging for Spark applications, you need to configure Spark to generate event logs. Modify your spark-defaults.conf file (usually located in the conf directory of your Spark installation) and add the following lines:
spark.eventLog.enabled true
spark.eventLog.dir file:///C:/spark/logs
spark.history.fs.logDirectory file:///C:/spark/logsStart Spark History Server
To start the Spark History Server, you can use the sbin/start-history-server.sh script included with your Spark installation. Navigate to the Spark directory and run the following command in Linux / MAC
./sbin/start-history-server.shFor windows navigate to the bin folder under Apache Spark installation directory then run below command
spark-class.cmd org.apache.spark.deploy.history.HistoryServerBy default, the Spark History Server will listen on port 18080. You can access the web UI by opening a web browser and navigating to http://localhost:18080