Apache Spark Installation on Windows: Apache Spark, the versatile open-source framework for big data processing, is a valuable tool for data analytics and machine learning. In this guide, we’ll take you through the process of installing Apache Spark on your Windows environment, making it accessible for all your data exploration and analysis needs.
Before we embark on the installation journey, let’s ensure you have the necessary prerequisites in place:
- An Operating system running Windows 10 or latest version.
- PowerShell or Command Prompt. We will use PowerShell in this tutorial. Right click on PowerShell then click on run as administrator.
Apache Spark Installation on Windows
While it’s commonly used on Unix-like systems, setting up Apache Spark on a Windows machine requires a few extra steps. In this detailed guide, we’ll walk you through each step to ensure you can smoothly install Apache Spark on your Windows environment.
Install Java
If Java is installed in your system you don’t have to follow this step.
Download Java: Download Java from here. Make sure to choose the appropriate version (64-bit or 32-bit) based on your system.
Run Installer: Run the JRE installer you downloaded and follow the installation wizard’s instructions. Remember the installation path as you’ll need it later.
Set JAVA_HOME: After installation, set the JAVA_HOME environment variable to the JRE installation directory. Here’s how:
[System.Environment]::SetEnvironmentVariable('JAVA_HOME','c:\Program Files\Java\jre-1.8',[System.EnvironmentVariableTarget]::Machine)Now add the JRE binaries to your system’s PATH environment variable:
$p = [Environment]::GetEnvironmentVariable("PATH", [EnvironmentVariableTarget]::Machine);
[System.Environment]::SetEnvironmentVariable('PATH',$p + ";%JAVA_HOME%\bin",[System.EnvironmentVariableTarget]::Machine)Install Python (Optional but Recommended)
- Download Python: If Python is not already installed, download the latest version of Python (Python 3.x is recommended) from the official Python website.
- Run Installer: Run the Python installer you downloaded and follow the installation wizard’s instructions. Ensure that you check the option to add Python to the system PATH during installation.
- Verify Installation: Open a command prompt and run the following command to verify the Python installation:
python --versionDownload Apache Spark
- Visit the Apache Spark official download page.
- Choose the Spark version that suits your requirements. We recommend selecting the “Pre-built for Apache Hadoop” package unless you have a specific Hadoop distribution you want to use.
- Click the download link corresponding to your chosen version. In our case we are downloading spark-3.4.1-bin-hadoop3.tgz
Extract Spark Archive
- Once the download is complete, navigate to the directory where the Spark archive is saved.
- Extract the archive using the following command
tar -xf .\spark-3.4.1-bin-hadoop3.tgz -C C:\sparkAdd winutils.exe
Apache Spark, despite being a separate project, shares some components and concepts with Apache Hadoop, an ecosystem for distributed storage and processing of large datasets. Spark’s original design involved working with Hadoop Distributed File System (HDFS) and other Hadoop components.
In Hadoop, file and directory permissions are managed differently than on Windows. Hadoop uses Unix-style permissions, whereas Windows uses its own security model. When Spark interacts with HDFS-like file systems, it expects certain Unix-like permissions, and this is where winutils.exe comes into play.
Download winutils.exe and hadoop.dll then put both into C:\spark\spark-3.4.1-bin-hadoop3\bin folder. Check different versions of winutils.exe and use accordingly for your requirements. In our case we are using hadoop-3.3.5 .
Configure Environment Variables
- Set the SPARK_HOME environment variable to the directory where Spark is extracted: For Windows (using PowerShell run as administrator):
[System.Environment]::SetEnvironmentVariable('SPARK_HOME','C:\spark\spark-3.4.1-bin-hadoop3',[System.EnvironmentVariableTarget]::User) - Set the HADOOP_HOME
[System.Environment]::SetEnvironmentVariable('HADOOP_HOME','C:\spark\spark-3.4.1-bin-hadoop3',[System.EnvironmentVariableTarget]::User) - Add the Spark binaries to your system’s
PATHenvironment variable:$p = [Environment]::GetEnvironmentVariable("PATH", [EnvironmentVariableTarget]::User); [System.Environment]::SetEnvironmentVariable('PATH',$p + ";%SPARK_HOME%\bin",[System.EnvironmentVariableTarget]::User)
Test the Installation of Apache Spark on Windows
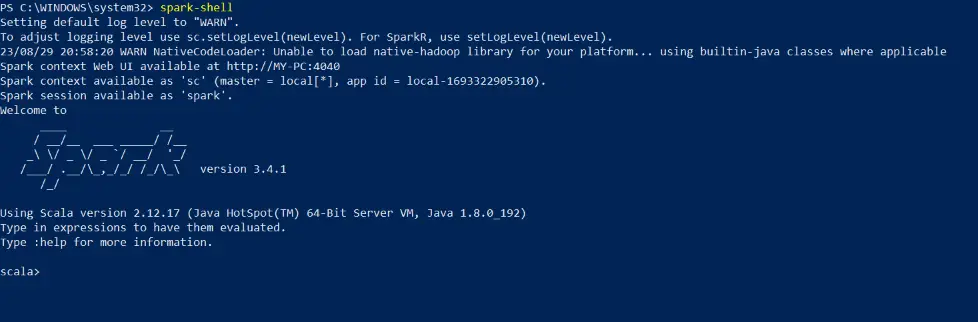
Now close the power shell and open again (run as administrator) then run the following command to launch the Spark shell:
spark-shellIf the Spark shell opens without errors and you see the Spark logo, congratulations! Apache Spark is successfully installed on your machine.
Run the “Hello, World!” Program: In the Spark shell, you can run a “Hello, World!” program using the println function. Type the following command and press Enter:
println("Hello, World!")Spark will execute the command, and you should see the output: Hello, World! Congratulations! You’ve just executed your first Spark program.
Exit the Spark Shell: To exit the Spark shell, simply type :q and press Enter. This is just the beginning of what you can do with Apache Spark for big data processing and analysis.
Launch Spark Applications
With your Spark installation complete, you’re now ready to create and run Spark applications on your Windows machine. Utilize the spark-submit command to submit Spark applications and unlock the capabilities of Spark for data processing, analytics, and more.
Conclusion
Congratulations! You’ve successfully installed Apache Spark on your Windows environment, including setting up Java, Python, and Hadoop native IO libraries. You’re now equipped to dive into the world of big data processing and analysis using Spark.
Frequently Asked Questions (FAQs)
Can I install Apache Spark on Windows?
Yes, you can install Apache Spark on Windows, but it’s not the most common environment for Spark. Spark is more commonly used on Linux or macOS. However, it is possible to set up Spark on Windows with some additional configurations.
What are the prerequisites for installing Apache Spark on Windows?
You’ll need Java (JRE), Python, and optionally Hadoop installed on your Windows machine. Java is a primary requirement for Spark.
Which version of Java should I use for Apache Spark on Windows?
Ensure that you have Java 8 or later installed, as Spark 3.x versions are compatible with Java 8 and higher.
Do I need Hadoop to install Apache Spark on Windows?
No, you don’t need Hadoop to install and run Apache Spark on Windows. You can use Spark in standalone mode without Hadoop.
What is the role of the winutils.exe file in Spark installation on Windows?
winutils.exe is a Windows utility needed if you’re working with Hadoop on Windows. It helps overcome certain issues related to Hadoop compatibility. You should download it and configure it as part of your setup.
How can I test if my Spark installation on Windows is successful?
You can open a Command Prompt and run the spark-shell command. If Spark starts without errors and you see the Spark shell prompt, your installation is successful.
Can I use PySpark on Windows?
Yes, you can use PySpark on Windows. Ensure that you have Python installed, and then you can install the pyspark package using pip to work with Spark using Python.
Where can I find more resources for Spark installation and usage on Windows?
You can refer to the official Apache Spark documentation for detailed information on installing and configuring Spark on Windows. Additionally, online forums and communities can be helpful for troubleshooting specific Windows-related issues.
