Different ways to Create RDD in Spark – In Apache Spark, Resilient Distributed Datasets (RDDs) are the fundamental data structures used for distributed data processing. RDDs can be created in several ways:
Create RDD in Spark – Parallelizing an Existing Collection
You can create an RDD from an existing collection in your driver program, such as a list or an array, using the parallelize method of the SparkContext. For example:
val data = List(1, 2, 3, 4, 5)
// We will use existing Spark Context sc from Scala console
val rdd = sc.parallelize(data)
rdd.foreach(println)
Now lets run the above Scala code line by line in spark-shell and see what’s the output
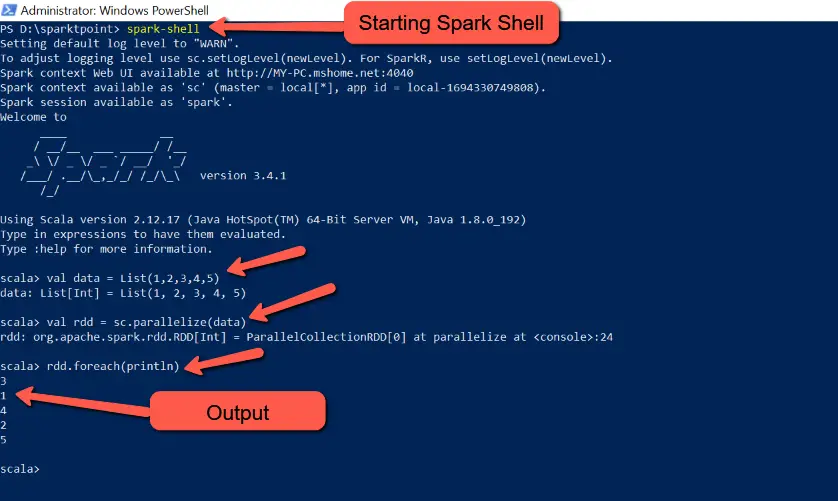
We can easily see below output is generating from spark shell
3
1
4
2
5Loading Data from External Storage
RDDs can be created by loading data from external storage systems like HDFS, local file systems, Amazon S3, or other supported data sources. You can use methods like textFile, wholeTextFiles, sequenceFile, or hadoopFile to create RDDs from these data sources.
// We will use existing Spark Context sc from Scala console
val rdd = sc.textFile("d:/file.txt")
rdd.foreach(println)
In the above example creating an RDD by reading data from a local file. This generates an RDD where every entry corresponds to a line within a file.
Transformations on Existing RDDs
You can create new RDDs by applying various transformations on existing RDDs. Common transformations include map, filter, reduceByKey, groupByKey, and many others. These transformations create a new RDD based on the operations applied to the original RDD.
val rdd = sc.parallelize(List(1, 2, 3, 4, 5))
val squaredRdd = rdd.map(x => x * x)
squaredRdd.foreach(println)Above code will produce below output
1
4
9
16
25External Data Sources
You can create RDDs from external data sources, such as databases, using libraries like Spark SQL or Spark Streaming. For example, you can use the jdbc method to read data from a relational database and create an RDD from it.
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder()
.appName("RDDCreationExample")
.config("spark.master", "local")
.getOrCreate()
val jdbcUrl = "jdbc:mysql://hostname:port/database"
val tableName = "table_name"
val jdbcProps = new java.util.Properties()
jdbcProps.setProperty("user", "username")
jdbcProps.setProperty("password", "password")
val df = spark.read.jdbc(jdbcUrl, tableName, jdbcProps)
val rdd = df.rdd
rdd.foreach(println)Creating Empty RDDs
You can create an empty RDD using the SparkContext.emptyRDD method and then populate it as needed.
val emptyRdd = sc.emptyRDD[Int]
From Pair RDD Operations
You can create RDDs by performing operations on pair RDDs (RDDs with key-value pairs) using transformations like mapValues, reduceByKey, or groupByKey. These operations result in a new RDD with potentially different keys and values.
val pairRdd = sc.parallelize(Seq((1, 'A'), (2, 'B'), (3, 'C')))
val valuesRdd = pairRdd.mapValues(x => x.toString.toLowerCase)
Output
(1,a)
(2,b)
(3,c)These examples demonstrate how to create Spark RDDs in Scala using different approaches, including parallelizing collections, loading data from external sources, applying transformations, working with external data sources, creating empty RDDs, and using pair RDD operations.
Conclusion
In conclusion, there are several ways to create Spark Resilient Distributed Datasets (RDDs), and the choice of method depends on your specific use case and data sources.
The flexibility to choose from these different methods for creating RDDs makes Apache Spark a versatile framework for distributed data processing, accommodating various data sources and processing requirements in big data applications. Your choice should be based on factors such as data size, data source, and the specific operations you intend to perform on the RDDs.
Create RDD in Spark Various Ways – Frequently Asked Questions (FAQs)
What is an RDD in Apache Spark?
An RDD (Resilient Distributed Dataset) is the fundamental data structure in Apache Spark. It represents a distributed collection of data that can be processed in parallel across a cluster.
What are the common ways to create an RDD in Spark?
The common ways to create RDDs in Spark include parallelizing an existing collection, loading data from external storage, applying transformations on existing RDDs, using external data sources, creating empty RDDs, and performing pair RDD operations.
When should I use parallelize to create an RDD?
You should use parallelize to create an RDD when you have an in-memory collection (e.g., a list or an array) and want to distribute it across a Spark cluster for parallel processing.
How do I load data from an external file to create an RDD?
You can load data from external files using methods like textFile, wholeTextFiles, or hadoopFile. These methods allow you to read data from various sources like HDFS, local file systems, or remote storage.
What are some examples of RDD transformations?
Common RDD transformations include map, filter, reduceByKey, groupByKey, flatMap, and distinct. These transformations are used to manipulate and process data within RDDs.
How can I create an RDD from an external data source like a database?
You can create an RDD from external data sources like databases using Spark SQL. Read data from the database into a DataFrame and then convert it into an RDD using the .rdd property of the DataFrame.
When would I need to create an empty RDD?
Empty RDDs are useful when you want to initialize an RDD and populate it with data later in your Spark application. They serve as placeholders for data that will be generated or loaded dynamically.
Which RDD creation method should I choose for my Spark application?
The choice of RDD creation method depends on factors like the size of your data, the data source, and the processing operations you plan to perform. Consider your specific use case to determine the most appropriate method for creating RDDs in your Spark application.